




近期,由Kaggle主办,Leica Microsystems和NVIDIA赞助的HPAIC(Human Protein Atlas Image Classification)竞赛正式结束。比赛为期三个月,共有来自全球的2236个队伍参加,极链AI研究院与工程院最终获得挑战赛金牌。
比赛介绍
蛋白质是人体细胞中的“行动者”,执行许多共同促进生命的功能。蛋白质的分类仅限于一种或几种细胞类型中的单一模式,但是为了完全理解人类细胞的复杂性,模型必须在一系列不同的人类细胞中对混合模式进行分类。
可视化细胞中蛋白质的图像通常用于生物医学研究,这些细胞可以成为下一个医学突破的关键。然而,由于高通量显微镜的进步,这些图像的生成速度远远超过人工评估的速度。因此,对于自动化生物医学图像分析以加速对人类细胞和疾病的理解,需要比以往更大的需求。
虽然这是生物学方面的竞赛,但是其本质是机器视觉方向的图像多标签分类问题,参赛队伍也包括许多机器视觉和机器学习领域的竞赛专家。
数据分析
官方给我们提供了两种类型的数据集,一部分是512x512的png图像,一部分是2048x2048或3072x3072的TIFF图像,数据集大概 268G, 其中训练集:31072 x 4张,测试集:11702 x 4张。
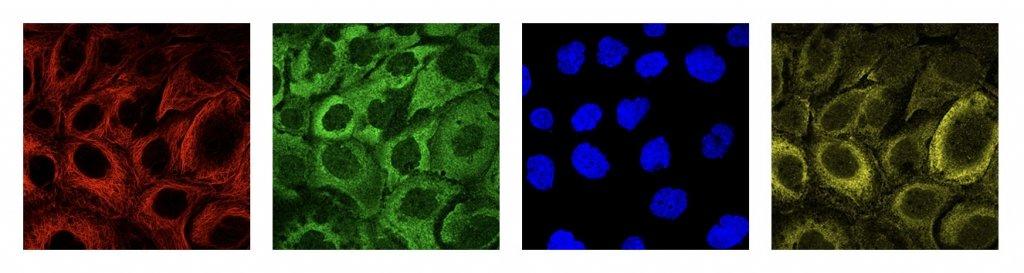
一个蛋白质图谱由4种染色方式组成(red,green,blue,yellow),图像示例如下:
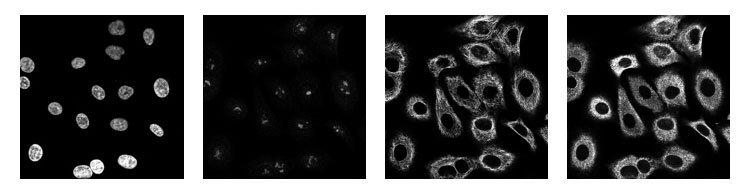
我们将4个通道合并成3通道(RYB)可视化的图像如下所示:

在本次竞赛中一共有28个类别,比如 Nucleoplasm、Nuclear membrane等,每个图谱图像都可以有一个或者多个标签。标签数量统计如下:
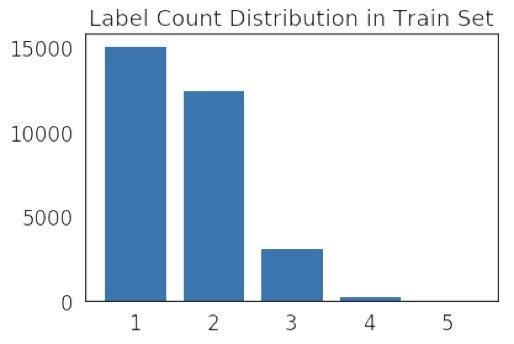
可以发现标签数量集中在1-3个,但是仍然会有图像有5个标签,给比赛增加了一定的难度。
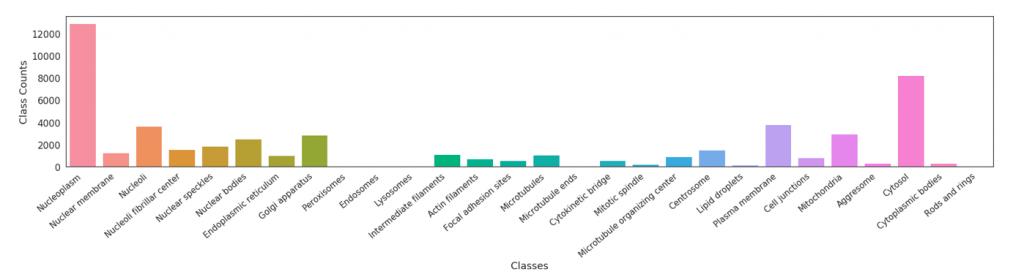
另一方面的难点是数据集中样本数量很不均匀,图像最多的类别有12885张,而图像最少的类别只有11张图像,这给竞赛造成很大的困难,样本数量分布情况可以在图中看出。
在比赛过程中逐步有参赛者发现官方的额外数据集HPAv18,并得到官方授权,这些数据集有105678张,很大程度的扩大了样本数量,同时给我们提供了很大的帮助。
环境资源
硬件方面我们使用了4块NVIDIA TESLA P100显卡,使用pytorch作为我们的模型训练框架。
图像预处理
HPAv18 图像与官方给出的图像有一定的差别,虽然也是由4中染色方式组成,但是每个染色图像是一个RGB图像,而不是官方的单通道图像,而且RGB三个通道的值差别较大,我们对这些图像做了预处理,对每个RGB图像只取一个通道(r_out=r,g_out=g,b_out=b,y_out=b),并将这些图像缩放到512x512和1024x1024两种尺度。
对于TIFF文件,我们用了一周的时间把这个数据集下载下来,然后将所有图像缩放到1024x1024。
数据增广
我们比赛中使用的增广方式有Rotation, Flip 和 Shear三种;因为我们不知道一张图像中的多个细胞之间是否有关联关系,所以比赛中没有使用随机裁剪的增广方式。
模型
我们最终使用的基础模型有Inceptionv3,Inceptionv4以及Xception三种,比赛前期我们测试了VGG,ResNet,ResNext,SeNet,但是效果不是很好,因此比赛末期没有再进行进一步测试。
我们使用了512,650和800三种尺度来增加网络对图像的理解,另外每个尺度进行10折交叉验证,保证验证集的划分对网络整体的影响,以及用验证集来评估模型预测的好坏和选择模型及其对应的参数。不同模型交叉验证时使用不同的随机种子划分验证集和训练集,以尽可能多的学到不同的样本组合。
Inceptionv3和Inceptionv4的512的结果不好(0.55+ public leaderboard 阈值0.15),因此没有做交叉验证,只是用512尺度训练了基础模型,并用在650和800的微调中。
模型修改:
1.第一层卷积的输入通道数由3修改为4,保持其他卷积参数不变,从而使网络应对4通道输入;
2.修改最后一的池化层为全局池化层,保证在多尺度时可以使用同一个网络;
3.全局池化后增加一层128的全连接,然后接一层28的全连接。
训练
训练过程的参数如下:
loss: MultiLabelSoftMarginLoss
lr: 0.05(512,imagenet 预训练),0.01(650和800,512预训练);
lrscheduler: steplr(gamma=0.1,step=6)
optimizer: SGD (adam,rms not well)
epochs: 25, 600和800一般在12-20直接提前结束,取loss最低的模型
10 folds CV
sampling weights:[1.0, 5.97, 2.89, 5.75, 4.64, 4.27, 5.46, 3.2, 14.48, 14.84, 15.14, 6.92, 6.86, 8.12, 6.32, 19.24, 8.48, 11.93, 7.32, 5.48, 11.99, 2.39, 6.3, 3.0, 12.06, 1.0, 10.39, 16.5]
scale:512,600,800
独立阈值
为每一个类别找到一个合适的阈值是一件很困难的事,但是多阈值是提升分数的关键,对我来说,大概可以提升0.005~0.008。 我们使用验证集来找阈值,我们训练单模型xception 512 ,验证集占13%。调整每一类的阈值使得f1 score达到最优,不过我们发现稀有类别的阈值普遍很高,public lb会变差,因此我们只调整了验证集1000张以上的类别,稀有类别控制阈值为0.15 通过这种方法找到的阈值在其他模型或者集成的时候同样有效。
测试
比赛结束以后我们将比赛中训练的模型重新提交查看private leaderboard成绩,得到如下结果:

比赛过程中我们发现做了10 fold ensemble不一定比single fold好,因此我们在最终集成的时候部分模型只选择了部分fold (根据loss选择)。
检索
我们使用检索的方法(特征使用inceptionv4 800 的128维特征)查找test与hpa相似的图片,使用余弦相似度进行度量,我们发现了许多相似的甚至相同的图片,直接使用相似度最高的300张图片的结果进行替换,分数在public lb上提升0.01~0.015,不过在private LB中并没有效果,官方在比赛过程中也说明部分test图像由于与HPA中部分图像重合,不再进行分数计算。
集成
我们将inceptionv3 inceptionv4以及xception 800的10fold 模型的特征进行concat(先进行l2),得到3840维的新特征,并在此基础上设计了2层的全连接网络进行训练, 并做10 fold CV,训练过程中使用不容参数训练过程如图所示,我们取了loss最低的参数。结果融合后private lb:0.55150 public lb:0.62791。

虽然上面方法在public lb上分数较高,但是当与其他模型结果融合时,public LB的分数反而降了,因此我们降低了这个模型的权重。
最后的结果是通过加权融合的方式得到的,权重根据模型的public lb分数设置, inceptionv4 800和inceptionv3 800的权重最高,xception 650 最低,同时也用到了inceptionv4、xception其他尺度的部分fold。


